Zapomeňte na Google, je tu Bing. Vyzkoušeli jsme budoucnost vyhledávání poháněnou umělou inteligencí
Nová verze vyhledávače Bing od Microsoftu ohrožuje Google a ukazuje budoucnost zkoumání internetu. Staví na umělé inteligenci od OpenAI.


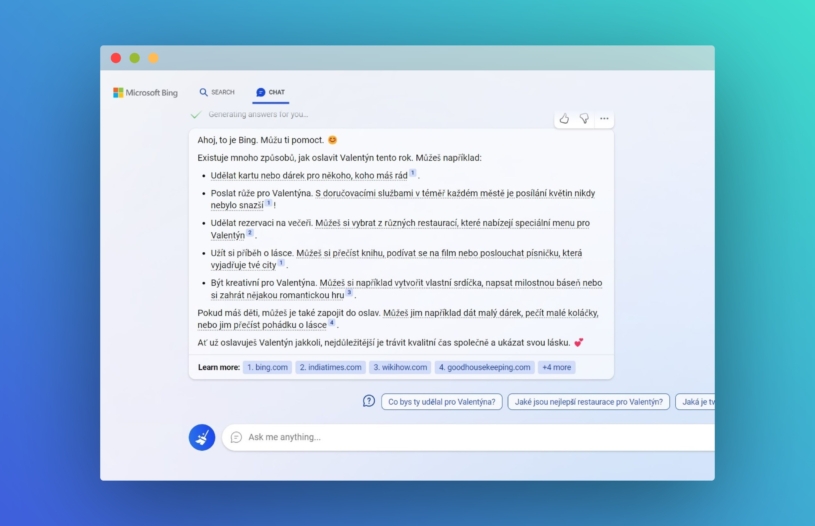
„Jak letos oslavit Valentýn?“ Pátrání na internetu v nové verzi vyhledávače Bing od Microsoftu začíná jako obvykle. Do příslušné kolonky ve vrchní části obrazovky napíšete, co chcete vědět, a systém vám ukáže seznam odpovídajících webových stránek seřazených pod sebou. Nová verze Bingu, který byl dlouhá léta kvůli nevalným výkonům spíše terčem posměchu, však po pár okamžicích vytahuje těžký kalibr. Na pravé straně se objeví okno s funkcí nazvanou Chat, kde vám odpověď vyjede v souvislém textu, tvrzení jsou navíc řádně ocitovaná, takže je lze ihned ověřit. Microsoft minulý týden do svého vyhledávače integroval textový generátor ChatGPT a hodil tak rukavici konkurenčnímu Googlu. Na novou verzi prohlížeče jsme se nyní měli možnost podívat i v CzechCrunchi.
Poté, co minulý měsíc Microsoft poslal miliardy do startupu OpenAI, který mimo jiné vyvíjí textový generátor ChatGPT, představil před týdnem podle očekávání novou verzi prohlížeče Bing, do kterého právě zmíněný program ChatGPT integroval. K dispozici je zatím po zapsání na čekací listinu. Technologie od OpenAI se stará o funkci nazvanou Chat, která běžné výsledky internetového vyhledávání přetaví do souvislého textu. Dokáže to navíc nejen v angličtině, ale i v češtině. Postup je stejný jako v případě jakéhokoliv textového nebo obrazového generátoru – uživatel napíše otázku či pokyn a program mu za okamžik odpoví.
Textové generátory, včetně toho od OpenAI, i přes své úctyhodné schopnosti odpovědět téměř na cokoliv také ukazují, že je stále potřeba jejich výsledky kontrolovat. Dokáží totiž věrohodně napsat i výmysl a nejde jim odkazování na původní zdroje. Proto jsem byl také zčásti skeptický, jak dobře bude program v dresu Microsoftu fungovat.
Nutno však podotknout, že generátor v prohlížeči je oproti samotnému programu ChatGPT o několik docela zásadních kroků napřed. Dokáže citovat zdroje, což je poměrně významný posun směrem k věrohodnosti jeho výtvorů, byť se určitě stále vyplatí řídit se heslem důvěřuj, ale prověřuj. Citace se objeví v podobě, kterou zná každý, kdo někdy psal ve škole seminární práci – číslo za konkrétním tvrzením odkazující na poznámku pod čarou, kde si lze rozkliknout danou webovou stránku, ze které program čerpal.
Nastartujte svou kariéru
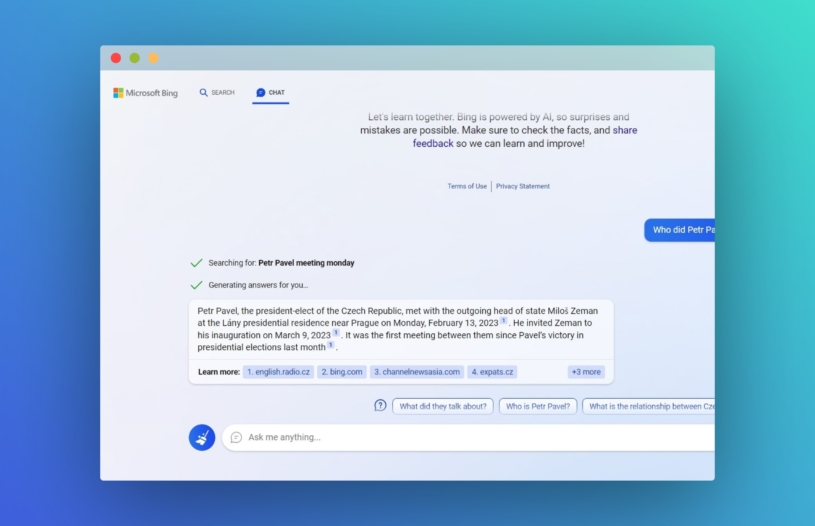
Více na CzechCrunch JobsUmělá inteligence v Bingu také sama brouzdá na webu. Umí tím pádem pracovat s aktuálními informacemi. Na rozdíl od samostatného ChatGPT, který má k dispozici jen informace do roku 2021. Nejenže si tak Bing dokáže poradit s nadčasovějšími problémy, jako je plánování dovolené, rešerše nebo oslava dne svatého Valentýna, řekne vám i to, s kým se v pondělí potkal zvolený český prezident Petr Pavel. Sešel se s končícím prezidentem Milošem Zemanem. Program k tomu navíc přidá i doplňující informace o Pavlovi a o událostech následujících po prezidentských volbách, jak si můžete prohlédnout v galerii níže.
I ChatGPT v Bingu samozřejmě není stoprocentní. Občas je třeba experimentovat s frázemi, které člověk při zadávání použije. Někdy navíc, jako v případě informací o schůzce Pavla a Zemana, program reagoval lépe na anglické podněty než na ty české. Obecně se ale podle krátké zkušenosti zdá, že český jazyk zvládá obstojně.
Právě kombinace schopnosti pracovat s aktuálními informacemi a citovat předkládaná tvrzení se z pohledu uživatele zdají tím nejzajímavějším posunem oproti samostatné verzi ChatGPT od OpenAI. Není divu, že se začíná mluvit o přelomovém okamžiku v historii internetového vyhledávání.
Na potvrzení tak odvážného tvrzení si ještě budeme muset počkat. Google teď každopádně musí hájit svou monopolní pozici na poli internetového pátrání a na ni navázaný obří příjem. Microsoft by s novými schopnostmi svého vyhledávače mohl ohrozit jeho dlouhodobou dominanci.
I proto Google taktéž minulý týden představil vlastní textový generátor Bard, zatím ovšem není dostupný široké veřejnosti. Oznámení programu Googlu se ale neobešlo bez komplikací, protože se ukázalo, že Bard v ukázkovém videu chybně odpověděl na otázku. Výsledkem byl pád hodnoty akcií mateřské společnosti Googlu Alphabet, upozornila agentura Reuters.
Dnešní suverén na poli vyhledávání platí za to, že zaspal. Je postavený na technologiích z devadesátých let, jak v rozhovoru pro CzechCrunch popsal odborník na umělou inteligenci Tomáš Mikolov, který pro technologického giganta dříve pracoval. „Já napíšu dotaz, ono mi to vrátí webové stránky, které plus minus obsahují klíčová slova. Ale přes neuronové sítě můžeme získat odpovědi a hledat věci, které nikdy nikdo nenapsal,“ vysvětlil Mikolov. V Googlu podle něj před deseti lety, kdy tam pracoval, „panoval názor, že vyhledávání nás živí, takže se na něj nesmělo v základu sahat. Pracují tam na něm tisíce lidí a myšlenka, že bychom ho od základu změnili, je děsila,“ uvedl Mikolov.
Vyhledávač, který využívá umělé neuronové sítě, na jejichž principu fungují generátory obsahu, navíc podle něj uživatelům brzy dokáže generovat obsah na míru. „Očekávám, že v blízké době budou modely personalizované a budou vracet různým lidem různé odpovědi, a to různým stylem,“ řekl Mikolov. Nastupující princip vyhledávání na internetu může do budoucna představovat zásadní problém pro vydavatelství a mediální domy, jak upozornil server Médiář. Protože umělá inteligence uživateli odpoví přímo v prostředí vyhledávače, ubyde důvod klikat na jednotlivé odkazy webů.
Přes rostoucí úspěch Microsoftu je jeho ředitel Satya Nadella spíše ve stínu byznysmenů jako Elon Musk, Jeff Bezos nebo Tim Cook. Dlouhodobě ale ukazuje, že opravdu ví, co dělá. Od doby, kdy Microsoft v roce 2014 převzal, vyrostla hodnota firmy sedminásobně. „Nadella musel Microsoft zevnitř překopat a přenastavit jeho mindset. Udělal z něj znovu technologickou firmu se vším všudy. Před jeho příchodem připomínala spíš General Electric než Google či Amazon,“ napsal o Nadellovi v komentáři kolega z redakce Luboš Kreč.